Gaussian mixture model is a widely used probabilistic model. For inference (model learning), we may use either EM algorithm which is a MLE approach or use Bayesian approach, which leads to variational inference. We would study this topic next week. For now, let us introduce one of the well-known nonparameteric methods for unsupervised learning, and introduce Gaussian mixture as a parametric counterpart.
K-means clustering Let us suppose that we know the total number of clusters is fixed as $K$.
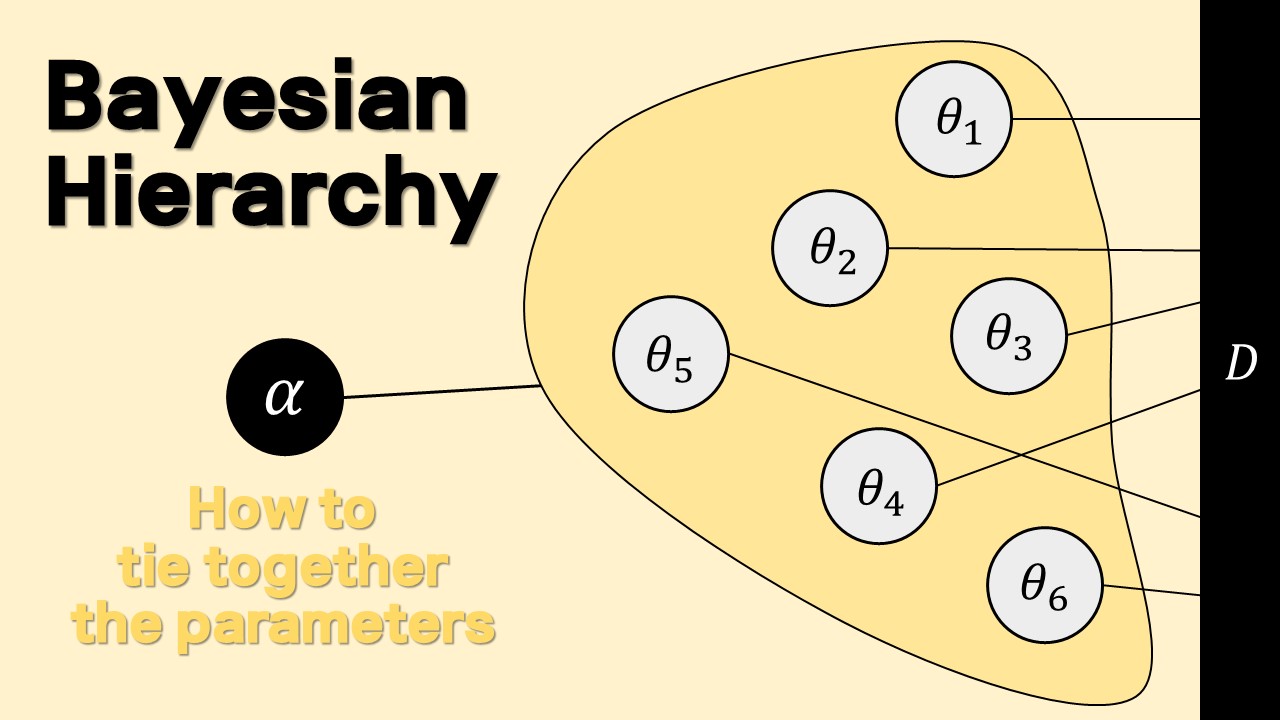
0. 개요 베이지안에서 모수에 대한 추론은 곧 모수의 분포를 구하는 것이다. 미지의 수에 대한 불확실성을 확률로 표현하였으니, 베이즈 정리를 이용해 데이터의 불확실성과 거짓말처럼 깔끔하게 같이 섞을 수 있기 때문이다. 그러나 아쉽게도 그 결과로 나오는 분포는 항상 깔끔하지만은 않다. 물론 데이터에 대한 모델을 지수분포족으로 한정하고, 그에 대응하는 또다른 특별한 지수분포족 분포함수를 사용하면, 사후분포의 모수를 쉽게 구할 수 있는데, 이러한 경우를 Prior-Posterior 간에 Conjugacy가 있다고 한다. 그러나 많은 경우 복잡한 데이터에 맞게 모델을 만들다 보면 해석적이지 않은 사후분포에 맞닥뜨리게 된다.
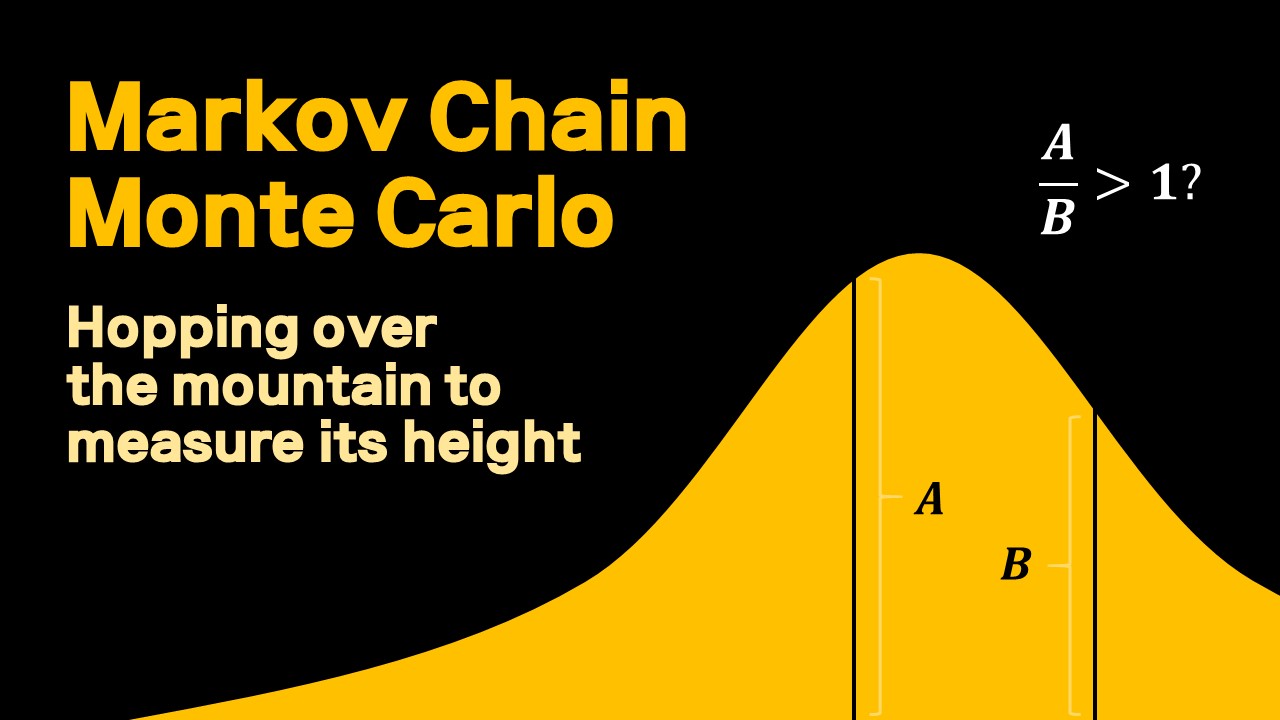
0. 이걸 왜 배우는데? 저번 시간에 간략히 살펴본 Gibbs Sampler는 MCMC(Markov Chain Monte Carlo), 즉 마코브 체인을 이용한 Posterior 분포 시뮬레이션 방법 중 하나인데, 이 MCMC 방법들이 도대체가 왜 잘 먹히는 지를 알려면 아무래도 마코브 체인에 대한 배경지식이 필요하다. 어떤 분포를 MCMC로 근사한다는 것은 모수 공간의 어떤 포인트에서 다른 포인트로 총총 점프하는 그 과정을 “잘” 구현해서, 마치 그 샘플들이 내가 모르는 그 분포에서 나온 것과 같다고 퉁치는 거다.
MCMC 이름의 의미
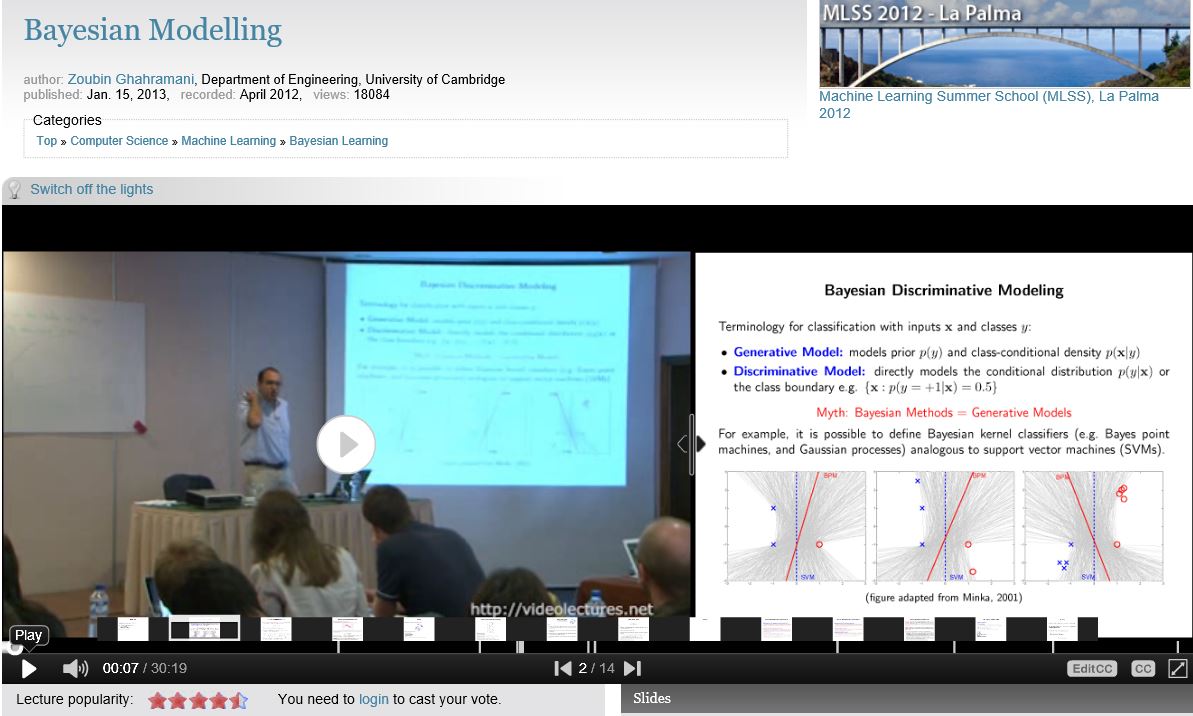
베이지안 머신러닝에 대해 인터넷에서 자료를 찾다보니 꽤 괜찮은 동영상 강의가 있어서 요약해보았다. 베이지안 모델링에 대해 개괄적으로 설명해주는 강의인데, 머신러닝에서 베이즈 정리가 어떻게 쓰이는지 잘 설명된 자료인 것 같다.
http://videolectures.net/mlss2012_ghahramani_bayesian_modelling/
위 링크에서 해당 강의 자료를 다운받고 시청할 수 있다. 다만 어도비 플래시가 있어야 구동이 되니 아마 올해가 지나면 못 듣지 않을까 싶다. 베이지안 모델링 외에도 Bayesian Nonparametrics, Graphical Model 등등 다른 다양한 강의가 있으니 한번 참고해보자.
아래에다가 강의 슬라이드별로 강의에서 아저씨가 말씀하신 부분을 나름 보충을 섞어 요약해놨다.
library(ggplot2) library(cowplot) library(reshape) Multivariate Normal Model Consider a bivariate normal random variable $[y_1, y_2]^T$. The density is written as ($p=2$)
$$ p(\mathbf{y}|\theta, \Sigma) = (\dfrac{1}{2\pi})^{-p/2}|\Sigma|^{-1/2} \exp{-\dfrac{1}{2}(\mathbf{y}-\theta)^T\Sigma^{-1}(\mathbf{y}-\theta)} $$
where the parameter is $\theta = \begin{pmatrix} E[y_1]\\\ E[y_2] \end{pmatrix}$ and $\Sigma = \begin{pmatrix} E[y_1^2]-E[y_1]^2 & E[y_1y_2]-E[y_1]E[y_2]\\\
E[y_2y_1]-E[y_2]E[y_1] & E[y_2^2]-E[y_2]^2 \end{pmatrix}$ $=\begin{pmatrix} \sigma_1^2 & \sigma_{12}\\\
\sigma_{21} & \sigma_2^1 \end{pmatrix}$.
Few things worth mentioning for multivariate normal model
the term in the exponent $(\mathbf{y}-\theta)^T\Sigma^{-1}(\mathbf{y}-\theta)$ is somewhat a measure of distance between mean and the data.
Inference for Normal Model Normal likelihood model has two parameters
$$ p(x|\theta, \sigma^2) = \dfrac{1}{\sigma\sqrt{2\pi}}\exp(-\dfrac{1}{2}(\dfrac{x-\theta}{\sigma})^2) $$ which requires a joint prior $p(\theta, \sigma^2)$. As for a single parameter case, we have joint posterior updated as
$$ p(\theta, \sigma^2|\mathbf{D}) \propto p(\theta, \sigma^2)p(\mathbf{D}|\theta, \sigma^2) $$ When our interest is in $\theta$, $\sigma^2$ is a nuisance parameter. Given the data $\mathbf{D}$ and the normal likelihood, we have three ways to deal with $\sigma^2$;