
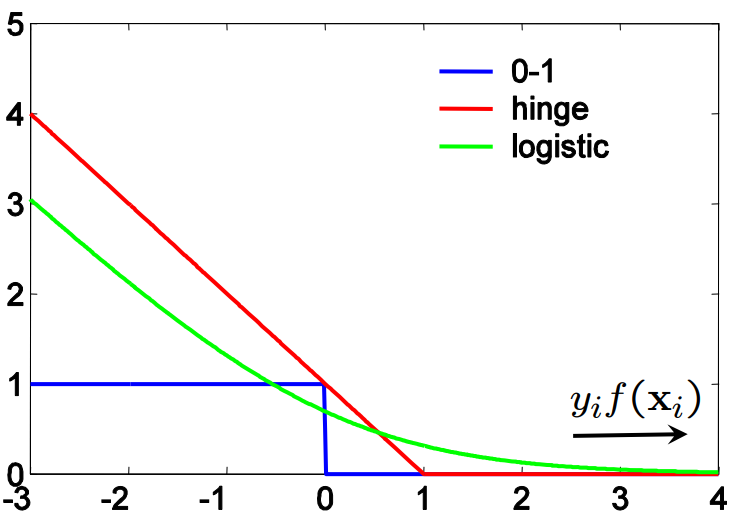
Logit Regression과 SVM은 Loss function의 차이
Jacobian cancels out the distortion in space brought by changing cooridinate system
학교 과제로 썼던 자료인데 조금 다듬어서 블로그에 올립니다.
I. Intro 2범주 범주형자료분석에서 여러 개의 연속형 응답변수가 주어졌을 때 쓸 수 있는 확률 모형의 대표적인 예는 로지스틱 회귀가 있다. 모델의 계수에 대한 해석이 가능한 Generalized Linear Model의 틀 안에 있기 때문에 결과에 대한 해석이 가능한 장점이 있다. 로지스틱 회귀는 로그 오드에 대한 선형식으로 Likelihood를 세워 MLE 방식으로 추정하는 함수적 추정 방법이다. 그러나 범주형자료분석에서 만일 목적이 예측이라면 해석이 불가능한 비모수적 함수 추정 방법을 쓸 수 있는데, 그 대표적인 예가 옆 동네 컴퓨터 공학과에서 처음 개발한 Support Vector Machine 방법이다.
