이제 대략적인 소개는 했으니 수식을 사용해 좀 더 자세히 설명해볼게요. 일단 데이터 형성 과정에 대한 우리의 가정을 Likelihood로 표현해봅시다.
$$ \begin{align} \text{Data (iid):}\quad &D = [x_1, x_2, …, x_n]\\\
\text{Sampling Density of $D$:}\quad& f(D|\theta) = \prod_{i=1}^nf(x_i|\theta) \quad (x_i\in \mathcal{X}, \theta \in \Omega)\\\
\text{Likelihood of $\theta$:}\quad& L(\theta|D) \end{align} $$
1. 빈도론적 세계관 이해하기 위의 가정은 빈도론과 베이즈 접근법에 상관없이 일반적으로 데이터의 형성과정을 확률 모델로 가정함과 동시에 성립하는 그냥 자명한 사실들입니다. 그러나 빈도론적 세계관에서는 이를 다음과 같이 다시 씁니다.
이제부터는 inference와 prediction 문제를 해결하는 통계학의 두 가지 접근법을 차례로 살펴보겠습니다. 첫 번째는 빈도통계학 접근법으로, 학부 통계학에서 가장 많이 접해본 내용입니다. 사실 그냥 통입 통방 수통1 수통2가 전부다 빈도통계학을 위한 준비 + 논리 이해하기입니다. 그래서 베이즈통계 안 듣고 졸업하면 통계학을 반쪽만 알고 가는거에요. 두 번째는 베이지안 접근법인데, 두 방법의 큰 차이점은 모수에 대한 해석의 차이라고 생각해요. 빈도통계학 접근법에서 추론이란 알지는 못하지만 단 하나의 상수로 존재하는 참 모수 $\theta$ 찾기에요. 우리는 한 번 확률 실험으로 얻은 데이터를 가지고 모수를 찾아야하는 참 안습한 상황에 처해있지요.
이처럼 데이터는 알고 모수는 모르는 상황에서, 우리는 오직 하나의 Likelihood 함수만 관측할 수 있습니다. 이 Likelihood 함수를 가지고 통계학자들이 하고 싶은 일은 두 가지로 요약할 수 있습니다.
Inference: 데이터 $\mathbf{x}$를 바탕으로 모수 $\theta$에 대해 무엇을 말할 수 있는가? Prediction: 데이터 $\mathbf{x}$를 바탕으로 새로운 데이터 $x_{new}$를 예측해보자. 동전의 예를 생각해보면, inference는 이 동전이 과연 fair한가 아닌가, 즉 앞면이 나올 확률이 무엇인가에 대해 답하고자 하는 것이며, prediction은 그렇다면 다음 시행에서 앞면이 나올지 뒷면이 나올지 예측하는 것입니다.
어떤 확률 변수 $x_i$가 가질 수 있는 값들을 sample space $\mathcal{X}$라고 하고, 그 값들의 분포는 어떤 모수 $\theta$에 의해 완전히 결정되는 함수 $f(x\mid\theta)$라고 생각해봅시다(예컨대 이항분포나 분산이 주어진 정규분포 등을 생각해볼 수 있겠습니다). 모수 $\theta$가 가질 수 있는 값들은 parameter space $\mathcal{\Omega}$라고 합니다. (이때 모수 $\theta$는 스칼라가 아니라 벡터일 수도 있습니다. 여기서는 스칼라인 경우만 일단 생각해볼게요.)
$$ \text{Sampling Density of $x_i$:}\quad f(x|\theta) \quad (x\in \mathcal{X}, \theta \in \Omega) $$
이때 함수 $f$를 probability density라고 합니다.
“Study hard what interests you the most in the most undisciplined, irreverent and original manner possible.” (Richard Feynmann)
About My name is Kang Gyeonghun (Korean: 강경훈, Pronunciation: Khane-gi-yeong-hoon). I am currently an undergraduate student in Yonsei University, Korea. I am majoring in Economics but I was disenchanted with that subject way back, and had dreamed of being an professional investor. I spent most of my eight semesters of undergraduate course studying corporate finance, accounting, portfolio strategy and such, along with an internship in a local private equity.
학교 과제로 썼던 자료인데 조금 다듬어서 블로그에 올립니다.
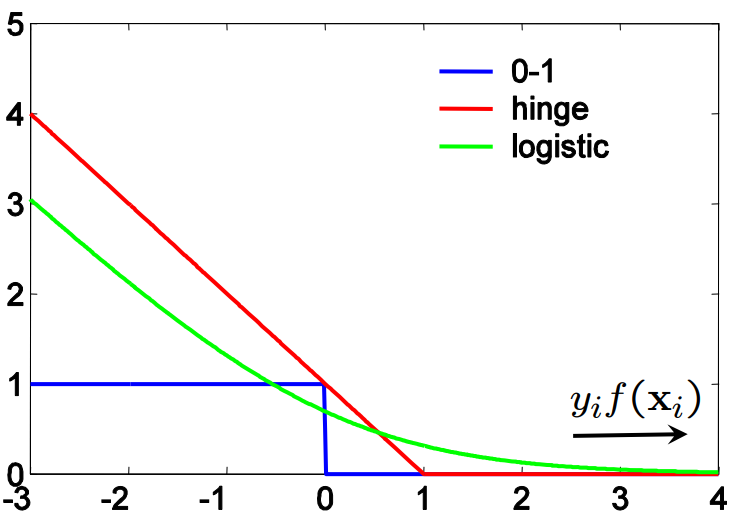
I. Intro 2범주 범주형자료분석에서 여러 개의 연속형 응답변수가 주어졌을 때 쓸 수 있는 확률 모형의 대표적인 예는 로지스틱 회귀가 있다. 모델의 계수에 대한 해석이 가능한 Generalized Linear Model의 틀 안에 있기 때문에 결과에 대한 해석이 가능한 장점이 있다. 로지스틱 회귀는 로그 오드에 대한 선형식으로 Likelihood를 세워 MLE 방식으로 추정하는 함수적 추정 방법이다. 그러나 범주형자료분석에서 만일 목적이 예측이라면 해석이 불가능한 비모수적 함수 추정 방법을 쓸 수 있는데, 그 대표적인 예가 옆 동네 컴퓨터 공학과에서 처음 개발한 Support Vector Machine 방법이다.
Optimization with inequality constraints 다음과 같은 최적화 문제를 생각해보자.
$$ \begin{align*} \textbf{Primal Problem:}\quad minimize &\quad f_0(\mathbf{x}) \quad (\mathbf{x} \in \mathbb{R}^n, ;domain;\mathcal{D})\\\
s.t. &\quad f_i(\mathbf{x}) \leq 0, \quad ^\forall i \in [m] \\\
&\quad h_i(\mathbf{x})=0 \quad ^\forall i \in [p] \end{align*} $$
우리가 익숙한 Lagrange Multiplier에서는 제약식이 등호로만 되어있었지만, 이제는 부등식이 추가되었다. 이러한 경우 부등호 조건식 $f_i(\mathbf{x})$를 inequality constraints, 등호 조건식 $h_i(\mathbf{x})$를 equality constraints라고 한다.
부등호 조건이 들어간 최적화 문제를 푸는 것은 참 막막한 일이다.