
Logit Regression과 SVM은 Loss function의 차이
Jacobian cancels out the distortion in space brought by changing cooridinate system
학교 과제로 썼던 자료인데 조금 다듬어서 블로그에 올립니다.
I. Intro
2범주 범주형자료분석에서 여러 개의 연속형 응답변수가 주어졌을 때 쓸 수 있는 확률 모형의 대표적인 예는 로지스틱 회귀가 있다. 모델의 계수에 대한 해석이 가능한 Generalized Linear Model의 틀 안에 있기 때문에 결과에 대한 해석이 가능한 장점이 있다. 로지스틱 회귀는 로그 오드에 대한 선형식으로 Likelihood를 세워 MLE 방식으로 추정하는 함수적 추정 방법이다. 그러나 범주형자료분석에서 만일 목적이 예측이라면 해석이 불가능한 비모수적 함수 추정 방법을 쓸 수 있는데, 그 대표적인 예가 옆 동네 컴퓨터 공학과에서 처음 개발한 Support Vector Machine 방법이다. 이 보고서에서는 비모수적 방법과 모수적 방법인 로지시틱 회귀와 SVM을 비교하고, 이 둘의 차이는 Classification Error를 어떻게 정의하냐의 차이로 귀결될 수 있다는 것을 보이고자 한다.
II. Support Vector Machine에 대하여
SVM을 간단히 설명하자면, 두 범주 $y_i \in {-1, 1}$에 속하는 데이터들의 데이터 스페이스 $\mathcal{X}$에서 어떤 Hyperplane을 그려서 데이터 스페이스를 두 범주로 분할하는 방법인데, 이 때 오로지 그려지는 Hyperplane에 가장 근접한 벡터들, 일명 support vector들만 사용하여 그려진다. 이때 그려지는 Hyperplane은 $y=f(\mathbf{x})=\mathbf{w^Tx}+b$로 나타낼 수 있는데, 여기에서 $\mathbf{w}$를 결정하는 방식이 Support Vector라는 이름이 붙은 이유를 설명한다. p차원 유클리드 공간인 데이터 스페이스 $\mathcal{X}$를 분할하는 어떤 Hyperplane $y=\mathbf{w^Tx}+b$에 대하여 이 Hyperplane과 임의의 데이터 벡터 $\mathbf{x}_i$ 간의 거리는
$\gamma_i := y_i(\dfrac{\mathbf{w^Tx_i}+b}{\mathbf{|w|}}) = \dfrac{y_1}{\mathbf{|w|}}(\mathbf{w^Tx_i}+b)$
으로 쓸 수 있다. 그렇다면 우리의 목적은 어떤 Hyperplane을 그렸을 때 그 Hyperplane과 데이터들 사이의 최소의 거리가 최대가 되게 하도록 Hyperplane을 그리는 것이며, 이 때문에 Maximum Margin Classifier라고도 한다.
$$
\arg\max_{\mathbf{w},b} \frac{1}{|\mathbf{w}|} \min_{i}y_i(\mathbf{w^Tx_i} + b)
$$
그러나 Hyperplane의 식을 생각해보면 계수 $\mathbf{|w|}, b$의 스케일은 Hyperplane의 위치를 결정하는데 아무런 영향이 없다는 것을 알 수 있다. 때문에 읨의로 $\min_i y_i(\mathbf{w^Tx_i}+b)=1$으로 고정해버려도 무방하므로, 위 식은 다음과 같이 쓸 수 있다.
$$
\begin{cases}
\min_{\mathbf{w},b} & \frac{1}{2} |\mathbf{w}|^2\\\
s.t. & y_i(\mathbf{w^Tx_i} + b) \geq 1 ;;^{\forall} i \in [N]
\end{cases}
$$
이는 부등호 조건이 주어진 제약 하 최적화 문제인데, Lagrange Duality를 사용하면 부등호 조건 최적화를 등호 조건 최적화 식으로 바꿀 수 있으며, 이로써 Hyperplane을 구한다.
(간단히 말하면 다음과 같다. 위의 최적화 문제에서 부등호 조건에 0보다 작다는 형식으로 바꿔보자. 그렇다면 위의 최적화 문제는 라그랑지안 식을 최대화하는 라그랑지안 계수를 찾고, 그렇게 최대화된 라그랑지안을 최소화하는 해를 구하는 것과 같다. 그러나 만일 목적식과 부등호 제약식이 convex하며, 등호 제약식이 affine하다면, 위 문제는 KKT 조건을 만족한다는 것이 알려져 있다. 그렇다면 위 문제의 해는 먼저 라그랑지안을 최소화하는 해를 찾고, 최소화된 라그랑지안을 최대화하는 라그랑지안 계수를 찾는 것과 동일하다. 그 이후에 구해진 라그랑지안 계수와 KKT 조건을 활용하여 원래 문제의 해를 구할 수 있다.)
그러나 데이터에 따라 어떤 하나의 선형 Hyperplane으로 어떠한 오차도 없이 데이터스페이스를 분할하는 것이 불가능할 수 있다. 이때는 약간의 오차를 허용할 수 있는데, 핵심은 개별 데이터의 오차를 제약하지 안돼 전체 오차의 총량을 제약하고, 그 제약하는 정도를 Regularization parameter $C$로 정하는 것이다. 이러한 Soft-penalizing 하에서 최적화 문제는 다음과 같이 쓰여진다.
$$
\begin{cases}
\min_{\mathbf{w}, b} & \frac{1}{2}|\mathbf{w}|^2 + C\sum_i^N \epsilon_i\\\
s.t. & y_i(\mathbf{w^Tx_i} + b) \geq 1 - \epsilon_i\\\
& \epsilon_i \geq 0
\end{cases}
$$
여기서 한번만 더 변형을 해보자. $f(\mathbf{x_i})=\mathbf{W^Tx_i} + b$으로 쓰자. 그리고 에러 $\epsilon_i$를 생각해보면, 분류가 잘 된 경우는 $\epsilon_i = 0 \geq 1-y_if(\mathbf{x_i})$일 것이고, 조금이라도 에러가 있으면 $\epsilon_i > 1-y_if(\mathbf{x_i})>0$가 될 것이다. 때문에 위의 식을 한줄로 쓰면 다음과 같이 쓸 수 있다.
$$
\min_{\mathbf{w}} \underbrace{C\sum_{i=1}^N max[0, 1-y_if(\mathbf{x_i})]}_\text{loss function} + \underbrace{\frac{1}{2}|\mathbf{w}|^2}_{\text{regularization}}
$$
뭔가 익숙한 형태가 되지 않은가? 마치 에러를 최소화하는데, 거기에 계수의 크기를 제어하는 Regularization term이 추가된 모습니다. 한번 로지스틱 회귀도 위의 식처럼 나타내보자.
III. 다시 보는 Logistic Regression
범주가 $y_i \in {-1, 1}$일 때 로지스틱 회귀식은 $\log \dfrac{P(y_i=1)}{1-P(y_i=1)} = f(\mathbf{x_i})=\mathbf{w^Tx_i}+b$이다. 이를 이용하여 Likelihood를 써보면 다음과 같이 쓸 수 있다.
$$
\begin{cases}
P(y_i=1|\mathbf{x_i}) &=\dfrac{1}{1+e^{-f(\mathbf{x_i})}}\\\
P(y_i=-1|\mathbf{x_i}) &= \dfrac{1}{1+e^{+f(\mathbf{x_i})}}
\end{cases}
\quad \rightarrow \quad P(y_i|\mathbf{x_i}) = \frac{1}{1+e^{-y_if(X_i)}}
$$
이를 전체 N개의 데이터의 Likelihood를 다 곱한 Joint Likelihood를 구하여, 이를 로그를 취하고 음수로 바꿔주면 다음과 같이 쓸 수 있다.
$$
\text{Negative log likelihood}\quad \sum_{i=1}^N \log{(1+e^{-y_if(\mathbf{x_i})})}
$$
이때 위의 식을 가만히 살펴보면, 로지스틱 회귀의 분류가 맞으면 $y_if(\mathbf{x_i}) > 0$이므로 $\log(1+e^{-y_i f(\mathbf{x_i})})$가 작아지며, 분류가 틀리면 $y_if(\mathbf{x_i}) < 0$이므로 $log(1+e^{-y_i f(\mathbf{x_i})})$가 커지는 것을 알 수 있다. 즉 마치 위 식을 **Loss function**으로 볼 수 있다는 것이다. Lasso와 Ridge가 선형회귀모델의 loss function에 Regularization Term을 추가한 것처럼 로지스틱 회귀에서 Regularization Term을 추가할 수 있다. 편의를 위해 $l_2$ regularization을 이용하면 다음과 같이 쓸 수 있다.
$$
\min_{\mathbf{w}} \underbrace{\sum_{i=1}^N log(1+e^{-y_i f(\mathbf{x_i})}) }_\text{loss function}+ \underbrace{\lambda |\mathbf{w}|^2}_\text{regularization}
$$
SVM에서 쓴 식과 같은 형태로 나타난 것을 볼 수 있다. 이게 무슨 의미일까?
IV. “Loss Function 차이죠?”
예측 목적의 알고리즘을 짤 때 가장 중요하게 고려해야할 것은 예측오차, 즉 Loss를 어떻게 정의할 것이냐이다. Classification에서는 제대로 분류된 관측치에 대해 0, 오분류된 관측치에 대해 1의 loss를 부여할 수 있는데, 이를 0-1 loss function라고 한다. 그러나 이 로스펑션은 불연속하기 때문에 예측 방법을 짤때 직접적으로 쓰기 힘드니, 이 함수를 다른 함수로 근사하는데, SVM은 hinge loss를, 로지스틱 회귀는 logistic loss를 사용해 이를 근사한다.
$$
\text{Logistic Error} \quad log(1+e^{-y_i f(\mathbf{x_i})}) \\\
\text{Hinge Error}\quad max[0, 1-y_if(\mathbf{x_i})]
$$
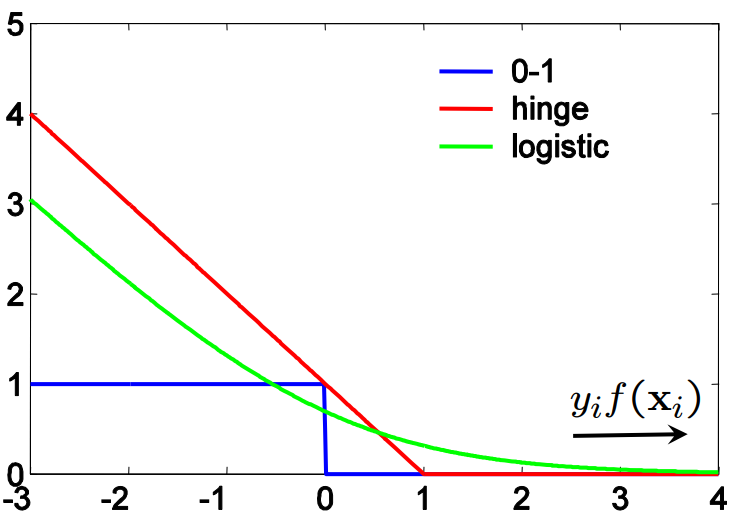
이를 그림으로 그리면 다음과 같다.
(출처 http://www.robots.ox.ac.uk/~az/lectures/ml/2011/lect4.pdf)
즉 SVM과 로지스틱 회귀는 결국 “Loss Function 차이"로 귀결될 수 있다는 것인데, 이것이 예측 모델의 성능에 미치는 영향은 바로 SVM은 Sparse하며, Outlier에 영향을 덜 받는다는 것이다.
우리가 어떤 예측 모델이 Sparse하다고 얘기할 때 의미하는 바는 모델의 학습에 필요한 데이터 수가 적다는 것이다. 왜 그럴까? $y_if(x_i)$가 1보다 큰 구간은 예측이 잘 된, 정확히 말하면 데이터 벡터가 seperating hyperplane의 양 옆의 어떤 마진 밖에 있는 구간이고, 0과 1 사이에 있는 구간은 에측은 잘 되었지만 그 마진 안에 있는 데이터이며, 0보다 작은 구간이 예측이 틀린 데이터인데, hyperplane에서 멀어질수록 그 값이 커지는 것을 볼 수 있다. 여기서 알 수 있는 점은, 초록색으로 보여지는 로지스틱 로스에서는 예측이 잘 되었든 못 되었든 모든 데이터에 로스를 부여하는 반면, SVM으로 그려지는 Hyperplane의 마진 밖에 있는 예측이 잘 된 데이터에 영향을 받지 않는다는 것이다. 또한 로지스틱 회귀에 비해 전체적으로 오분류된 관측치에 가해지는 패널티가 더 크며, 반대로 잘 분류된 데이터에 대해서는 그 어떤 로스도 없다. 때문에 전체 데이터 중에서 Hyperplane 주위에 있거나 예측이 잘못된 데이터만 고려하기 때문에 Sparse 하며, 이 때문에 SVM을 Sparse Kernel Machine으로 부르기도 하는 것이다. 이는 즉 Hyperplane으로부터 일정 거리 떨어지기만 하면 데이터가 어떻게 변동을 하든 영향을 안 받는 것이기 때문에, 로지스틱 회귀에 비하여 데이터의 변동에 따른 영향이 적음을 알 수 있다.
V. 결론: 그래서 무엇을 쓸 것인가?
이상의 논의를 종합하면 SVM과 로지스틱 회귀의 차이는 Loss function에 대한 근사의 차이이며, 예측 오차를 줄이는 것이 목적인 경우 데이터를 적게 사용하고, outlier의 영향이 적으며, 오분류 관측치에 대한 로스가 더 큰 SVM을 쓰는 것이 유리하다는 결론을 낼 수 있다. 그러나 이는 어디까지나 예측의 목적일 뿐이기에, 만일 데이터 분석의 목적이 해석이면 로지스틱 회귀를 쓰는 것이 알맞다. 로지스틱 회귀에서 모델의 계수는 설명변수가 한 단위 증가할 때 로그 오드의 증감이라는 명확한 의미를 가지고 있으나, SVM의 hyperplane으로는 이러한 해석이 불가능하기 때문이다.
Refernces:
- Pattern Recognition and Machine Learning, Bishop
- Machine Learning: a Probabilistic Perspective, Murphy
- Introduction to Statistical Learning, James et al
- Support Vector Machine http://cs229.stanford.edu/
- Lagrange Duality http://www.stat.cmu.edu/~ryantibs/convexopt/
- Logistic Regression and SVM http://www.robots.ox.ac.uk/~az/lectures/ml/2011/lect4.pdf
